Day 0, captured the moment the sitemap went in.
A fair test of "can a clean site rank fast" needs an honest starting line — proof that there was nothing to start from. So here is the baseline, straight out of Google Search Console on 4 June 2026, the day the property was verified and the sitemap submitted. No prior crawl history, no backlinks, no legacy URLs, no brand searches. Zero footprint.
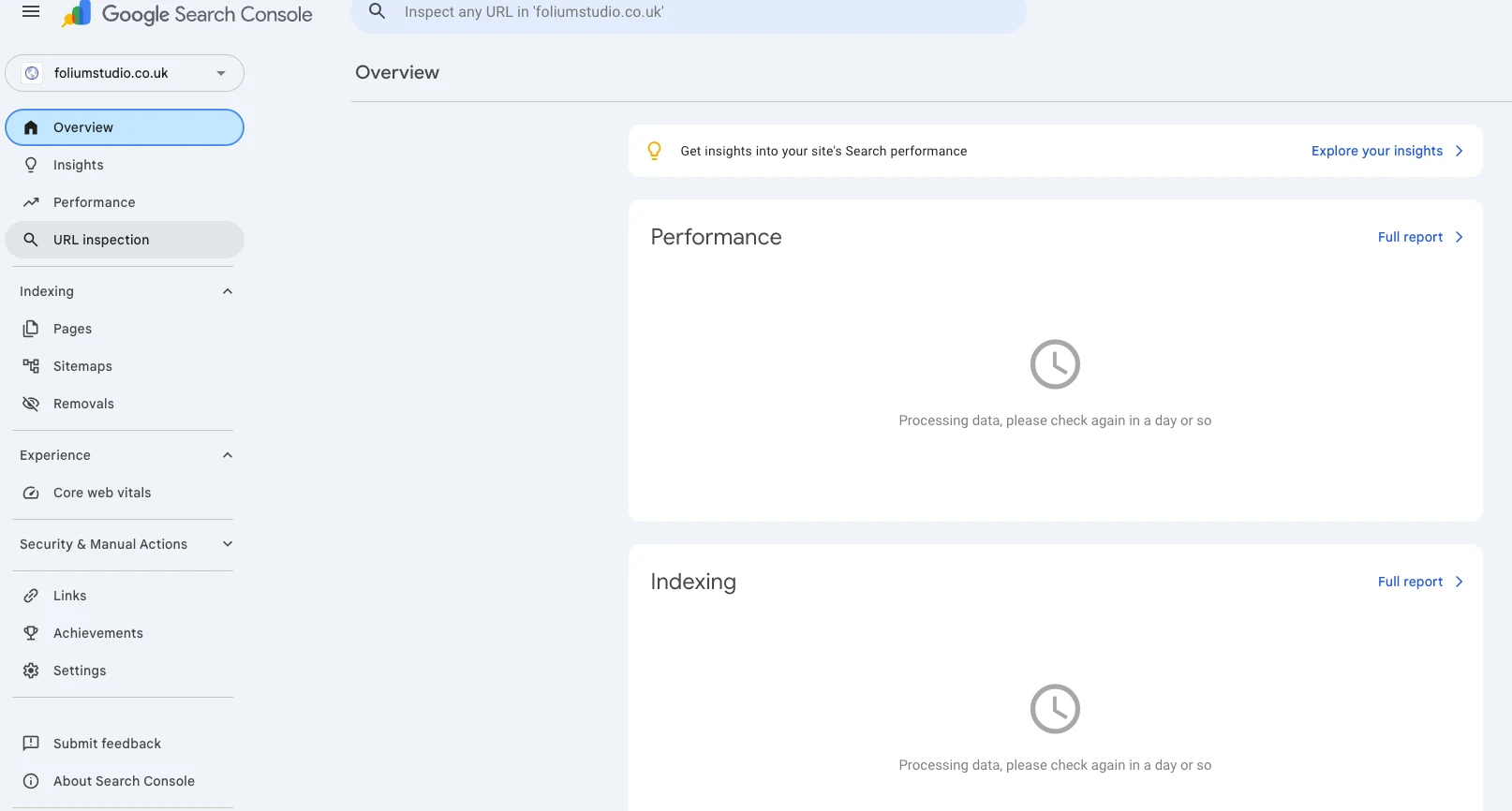
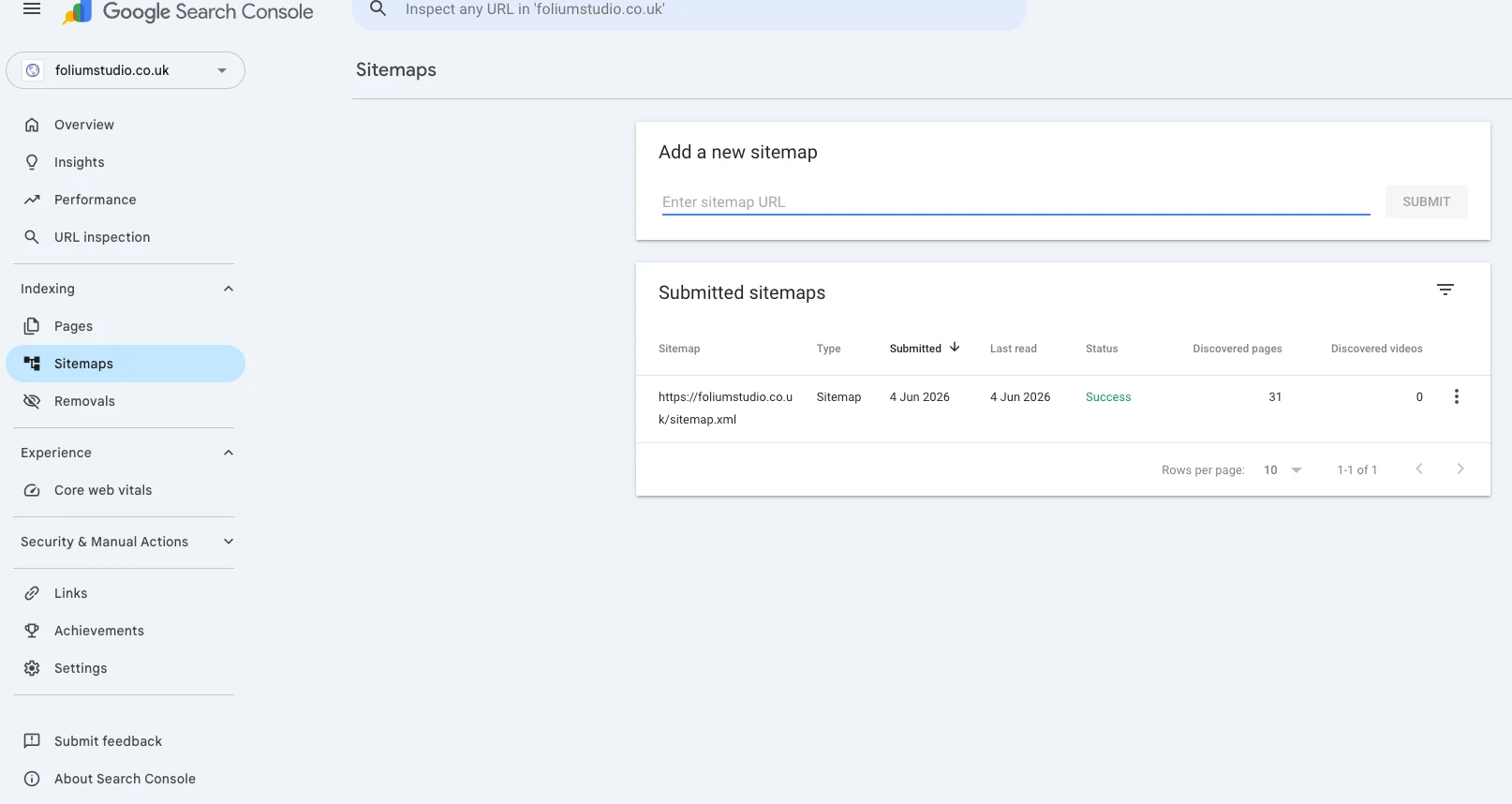
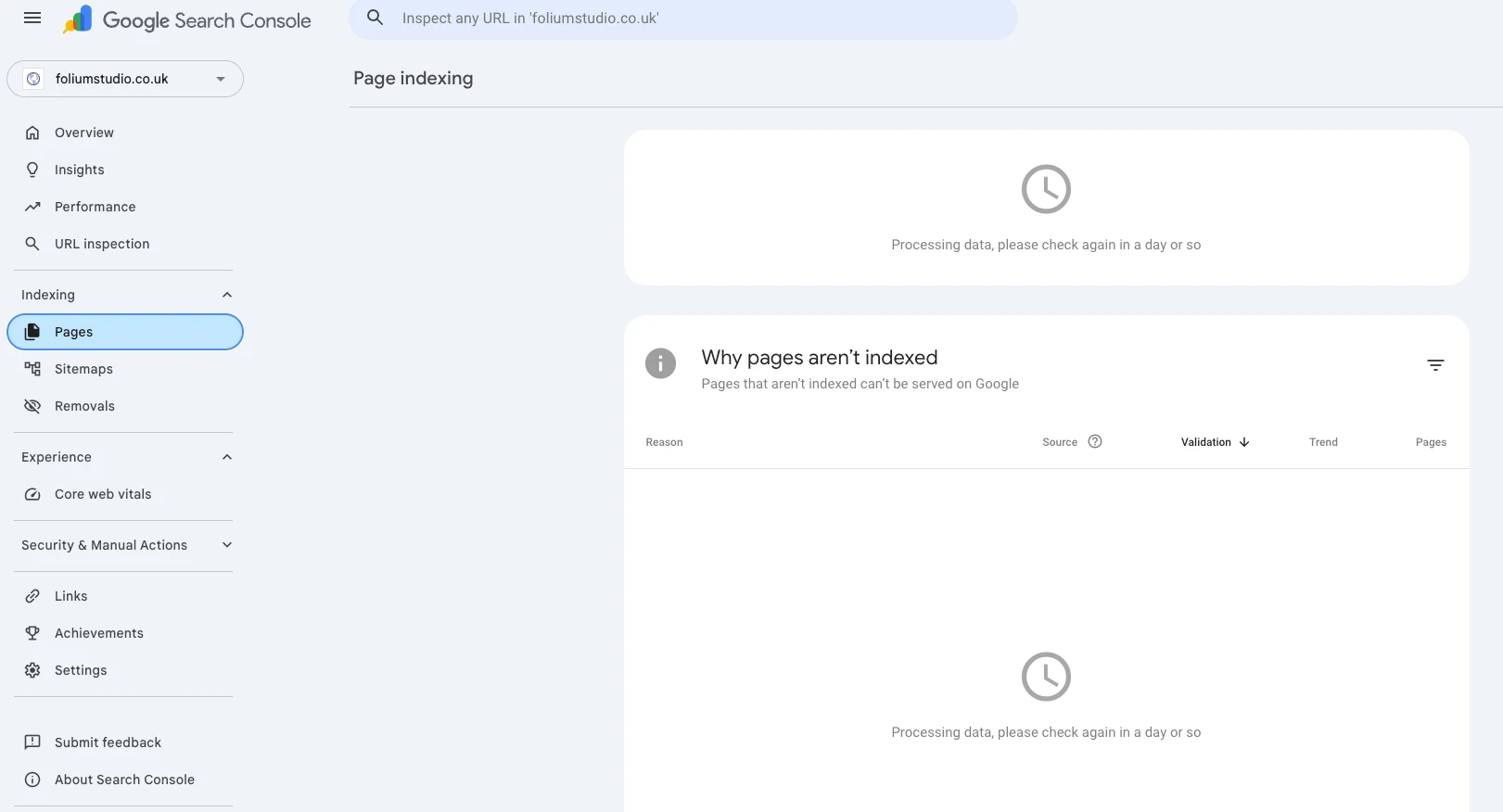
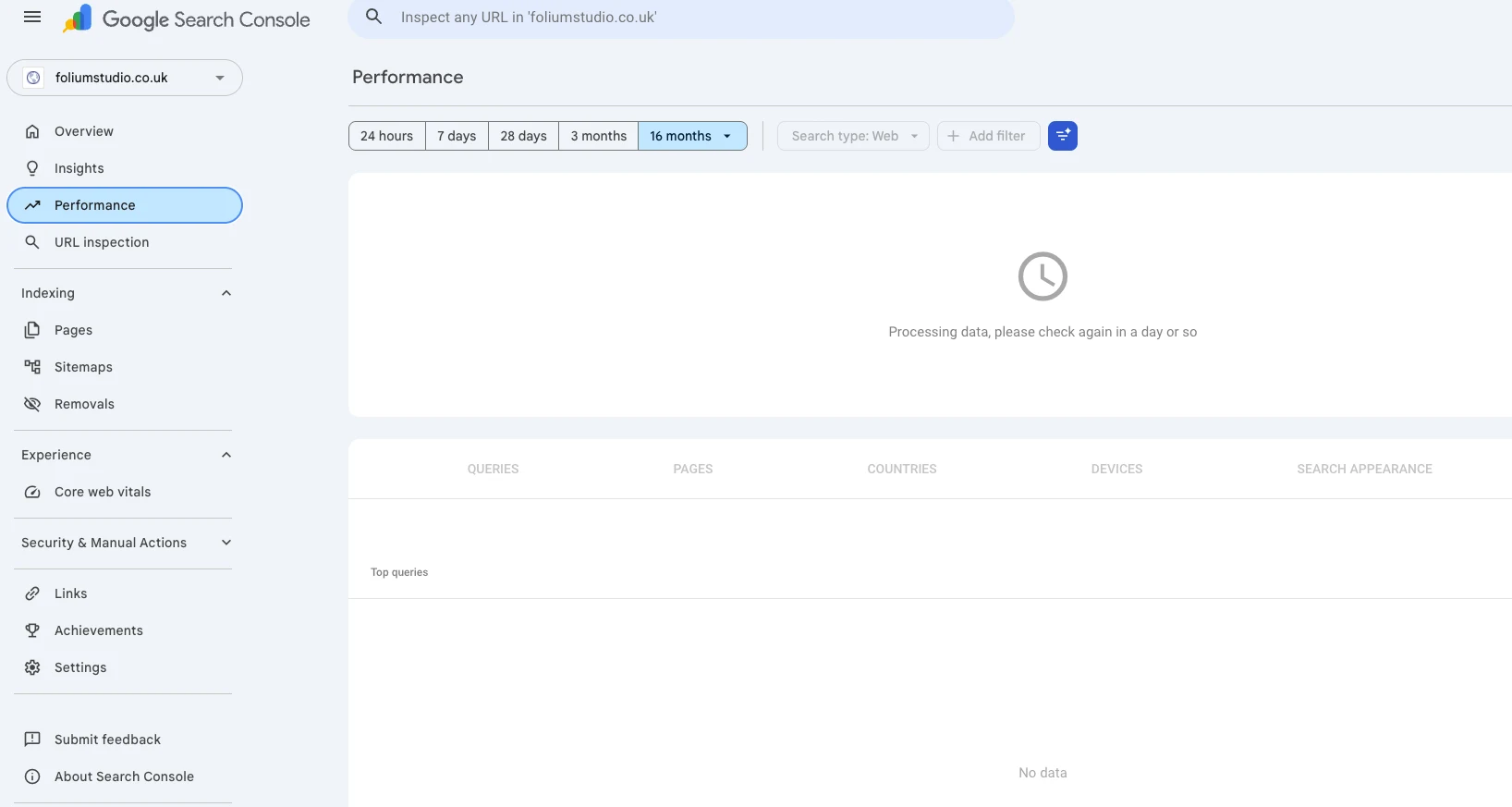
Inspecting the homepage URL directly says the same thing in plainer words: “URL is not on Google — Discovered, currently not indexed.” Discovery source: the sitemap. Referring page: None detected. Last crawl: N/A. That is exactly the state you want at the start of this test — Google knows the pages exist (via the sitemap, not via a single inbound link) and simply hasn't got to crawling and indexing them yet.
That is the whole point of the screenshots: there is genuinely nothing here yet. Every chart says processing or not enough data. The only positive signal is that Google read the sitemap cleanly and found all 31 pages on the first pass — which is the one thing a static site gets for free that a slow, JavaScript-heavy one often fights for. From here, the only direction is up, and every step is timestamped.
What a clean site is supposed to do — and why it should be fast.
The bet isn't that we'll outspend anyone on links. It's that the things search engines and AI models actually reward are structural, not accumulated — and a site built correctly from the first commit starts with most of them already in place. The moves below are what the site shipped with on Day 0; the rest of this case study is whether they pay off, and how quickly.
-
Crawlable on the first read.
Pre-rendered static HTML with the content in the markup — no client-side rendering for a bot to wait on. Google found 31 pages from one sitemap on the first fetch, with nothing deferred behind JavaScript.
-
Correct, connected structured data.
Every page carries valid schema.org JSON-LD — Organization, WebSite, Article, FAQPage, BreadcrumbList — wired into a single entity graph. This is what lets a model state who we are and what we do without guessing.
-
An AI-readable corpus.
A hand-written
llms.txtandllms-full.txtgive assistants a clean, quotable source of truth. The on-site assistant already grounds its answers on it — the same surface ChatGPT, Gemini and Perplexity read. -
Depth, not filler.
A dozen long-form articles and worked case studies, each answering a real question end to end. Content that resolves intent is what gets cited in an AI answer — and increasingly what ranks in the blue links too.
-
Sub-second performance as a baseline, not a project.
Mobile Lighthouse in the 90s, sub-second LCP, near-zero layout shift — on the edge, at £0/month. Speed is a ranking input and a citation input; here it's the default state of every page, not something bolted on later.
That last point isn't aspirational — it's already true, on the same day as the empty baseline above. Here is the homepage through Google's own PageSpeed Insights, captured 4 June 2026:
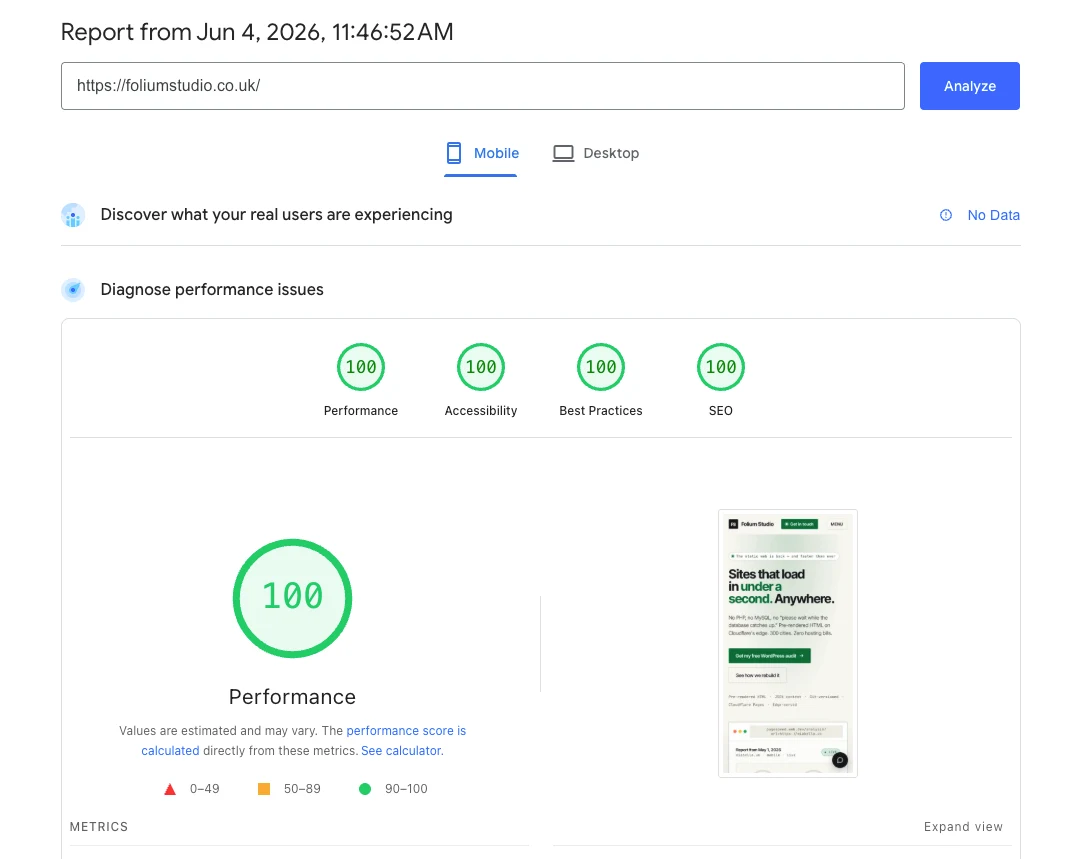
A clean 100 across the board — Performance, Accessibility, Best Practices and SEO — on mobile, on a domain with zero traffic and zero history. The site is fast and technically clean from the first day it exists, before a single visitor arrives. That's the difference between speed as a property of the build and speed as a project you pay to retrofit later. The ranking experiment starts from a page Google has no technical reason to hold back.
You can view the full PageSpeed Insights analysis for the homepage — the numbers are Google's, not ours. A note in fairness: PageSpeed is a live test, not a fixed grade. Scores move a point or two between runs with Google's server load, the time of day, and network conditions, so treat this as one representative run rather than a permanent badge.
Putting our money where our mouth is.
It is easy to sell AI visibility with someone else's site and a flattering screenshot. It is harder to point a search engine at your own brand-new domain, publish the empty starting line, and let everyone watch what happens next. That is the version worth trusting — so that is the one we're running.
“If we can't rank our own clean, fast, well-structured site from a standing start, you should not believe we can do it for yours. So here's the standing start — dated, public, and ours.”
This is also the most honest demonstration of the brand itself. Folium is a new leaf on a web that's being reborn — static, owned, fast, cited by machines instead of buried under plugins. A zero-footprint domain is the cleanest possible place to test whether that thesis holds. No legacy, no shortcuts, no backlinks bought in the dark. Just the method, and a clock.
The AI crawlers got there first — by fifteen hours.
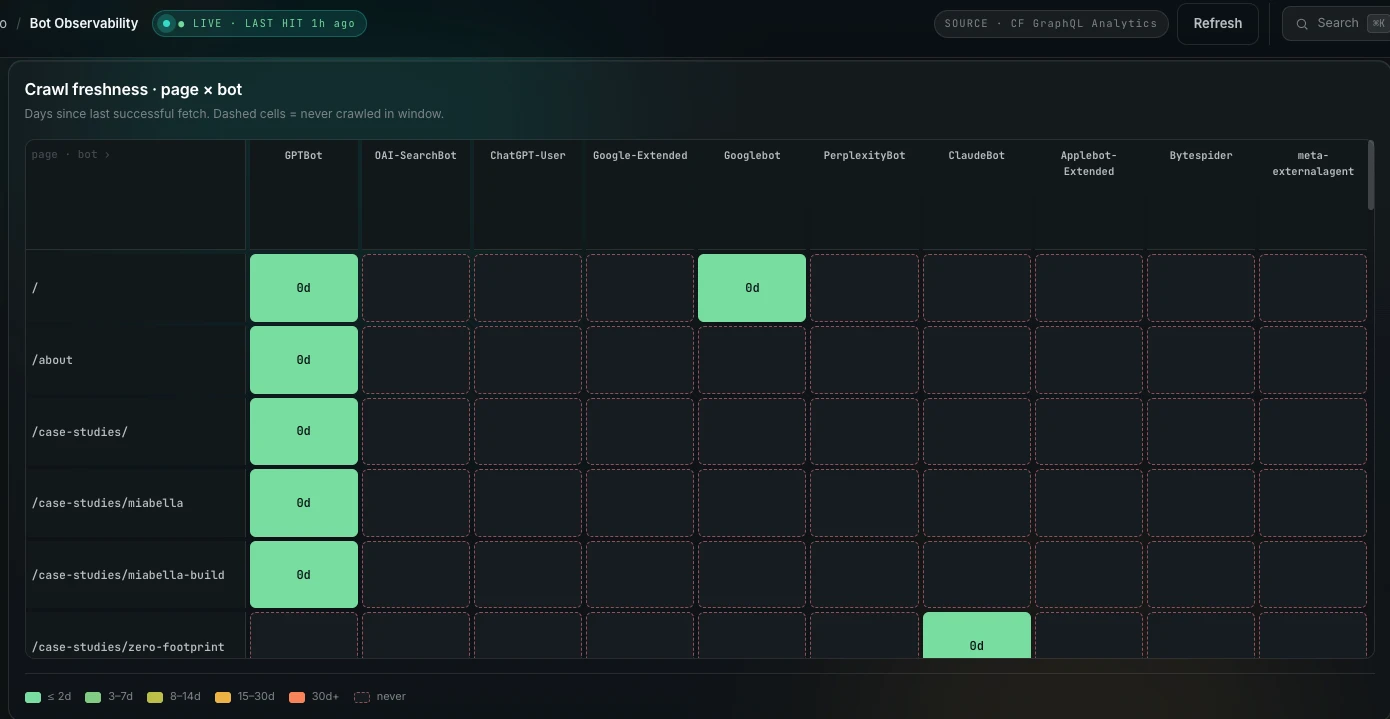
There's a difference between what an AI says about you and what it has actually fetched. Most tools only measure the first. This is the second: verified-bot crawl activity read straight from Cloudflare over the first eighteen hours the site was live (3–4 June 2026). The headline writes itself.
| Crawler | First fetch | Content pages | Hits |
|---|---|---|---|
| GPTBot · OpenAI training | 3 Jun, 18:00 | 29 / 31 | 55 |
| OAI-SearchBot · OpenAI search | 3 Jun, 18:00 | — | 1 |
| ClaudeBot · Anthropic training | 3 Jun, 21:00 | 2 (incl. this page) | 22 |
| Googlebot · Google search | 4 Jun, 09:00 +15h | 1 | 28 |
The first crawler hit the site at 18:00 on 3 June — within the hour of the first pages going live. It was OpenAI's GPTBot, and over the next three hours it fetched 29 of the 31 content pages: the entire Writing section, every service page, all four case studies. ClaudeBot arrived around 21:00 and went straight for this case study and the thank-you page. Googlebot didn't take its first fetch until 09:00 the next morning — a full fifteen hours behind OpenAI — and even then Search Console still read “discovered, currently not indexed.” (Honest footnotes: GPTBot chased one draft URL that now 404s, and Googlebot caught the homepage mid-redirect. Both are in the log; neither dents the coverage.)
That ordering is the entire argument. The crawlers feeding the answers ChatGPT, Gemini and Claude give reached a zero-footprint domain first, and read 94% of it, before Google's index had taken a single page. For a studio whose pitch is visibility in AI answers rather than just blue links, that's the leading indicator — being seen is upstream of being cited, and here the model-makers' own bots were reading the whole site inside a day. The citations are what the scoreboard below is now waiting on.
What gets added here — with dates — as the data lands.
The cards below are the milestones we're watching. Each one gets filled in with the date it happens and a screenshot to match, exactly like the Day 0 baseline above. Nothing here is claimed until it's shown.
First pages indexed.
The date Search Console moves pages from "discovered" to "indexed", and how many of the 31 make it in on the first wave.
First impressions and first ranked query.
The first queries the site surfaces for in Google — and the first one where it lands on page one.
First citation in an AI answer.
The first time ChatGPT, Gemini, or Google's AI Overview grounds an answer on the site and names it as a source.
First branded searches.
When "Folium Studio" starts showing up as a query in its own right — the signal that the name is entering circulation.
Real-user Core Web Vitals.
The point at which there's enough field traffic for the Core Web Vitals report to populate — and what it says.
First organic backlinks.
The first inbound links the site earns on merit, with no outreach campaign behind them.
Check back as the clock runs. This page is updated in place, and each milestone keeps its date so the timeline stays honest — the whole value of the experiment is in when each thing happened, measured from a verifiable zero.
Ranking #1 isn't the same as getting cited by AI.
Why this experiment tracks two scoreboards at once — the blue-link rank and the AI citation — and why the second one is the one most businesses can't see yet.
Read the piece → Writing · the methodAI is making stuff up about your business.
The structural fix this whole domain is built on: give the models something solid to ground on, and they stop fabricating. A zero-footprint site is the cleanest test of it.
Read the piece →